Синтезаторы речи онлайн: лучшие сервисы для озвучивания текста
Содержание:
- Встроенные приложения
- Некачественный датасет
- Дополнительные эксперименты
- SOVA
- Планы
- 4 Продвигай соцсети
- Озвучка английского текста голосом онлайн
- Какие возможности у онлайн сервисов по озвучиванию текста и зачем они нужны?
- Синтезатор речи (TTS)
- Гео персонажи
- Место № 10. Oddcast.com – позволит прочитать текст голосом онлайн на любом языке
- Как озвучить текст документа в Ворде — функция «Прочитать вслух»
- 3 Найди агента
- Популярные голосовые движки
- Приложения для чтения книг голосом
- Озвучка текста естественным голосом с помощью нейронной технологии WaveNet
- 6 Запишись на курсы актерского мастерства
- BookSeer
- Краткий Обзор Решений
Встроенные приложения
Многие производители поставляют специальные утилиты для настройки голоса вместе со звуковыми картами и материнскими платами.
С помощью некоторых из них можно с легкостью поменять свой голос в режиме реального голоса. Решают они эту задачку великолепно, поскольку используют специальный аудио чип.

Интерфейс
Например, у меня стоит звуковой чип Creative Sound Core 3D, а в комплекте идет ПО Sound Blaster Pro Studio.
Вкладка CrystalVoice в программе позволяет не только очистить голос от посторонних шумов, но и сделать голос робота, инопланетянина, ребенка и т.д.
И работают эти эффекты прекрасно.
Некачественный датасет
Нам повезло, что в команде есть человек, увлекающийся музыкой, так что для облагораживания датасетов, в частности Руслана, мы вручную подбирали параметры различных фильтров и обрабатывали ими аудиодорожки в Logic Pro X. Ниже можете прослушать примеры оригинального и прошедшего обработку Руслана:
Также стоит отметить, что в датасете немного почищена пунктуация, так как движок реагирует на неё весьма чувствительно.
Дополнительные эксперименты
После решения всех насущных вопросов встала задача улучшить и разнообразить звучание, придать ему изюминки. Любой знакомый с темой скажет «Ок, посмотрите в сторону GST и VAE », и мы посмотрели.
Введение в пайплайн GST, на субъективный слух автора, не давало каких-то особых запоминающихся изменений, пока мы не попробовали подход, описанный в Text predicted GST – предлагается модели самой подбирать комбинацию стилистических токенов, чтобы добиться лучшего звучания для текущего текста. Для демонстрации работы этого модуля приведём аудио, полученные моделью, которая обучалась на датасете реплик персонажей из популярных зарубежных сериалов (актриса озвучки Екатерина). Уточним, что датасет изначально не предназначался для синтеза.
В общем, как и в жизни: главное найти подход к человеку.
Что касается использования вариационных автоэнкодеров, то эксперименты пока продолжаются, и похвастаться на данный момент нечем, так как столкнулись с определёнными проблемами. Если интересны технические детали — прошу под спойлер.
К тому же, так как мы часто слышали вопрос «А можно ли управлять скоростью и высотой тона речи?», мы добавили небольшой инструментарий для проведения этих операций на сгенерированных записях.
SOVA
В тексте неоднократно упоминалось, что мы выложили в открытый доступ часть своих наработок по синтезу. Вот их список:
- sova-tts-engine – движок на базе Tacotron 2 от NVIDIA. Всё вышеперечисленное, за исключением text predicted GST и VAE, было опубликовано в этом репозитории, плюс проведён избирательный рефакторинг кода;
- sova-tts-tps – тот самый nlp-препроцессор;
- sova-tts-vocoder – практически не изменённый вокодер от NVIDIA, но всё-таки с отличиями;
- sova-tts-binding – пакет для связывания nlp-препроцессора, движка и вокодера в единый инференс-пайплайн. Реализован с прицелом на добавление новых движков и вокодеров;
- sova-tts – упакованный в докер стенд синтеза с простеньким GUI интерфейсом;
- Почищенный датасет и веса Руслана (This work, «SOVA Dataset (TTS RUSLAN)», is a derivative of «RUSLAN: Russian Spoken Language Corpus For Speech Synthesis» by Lenar Gabdrakhmanov, Rustem Garaev, Evgenii Razinkov, used under CC BY-NC-SA 4.0. «SOVA Dataset (TTS RUSLAN)» is licensed under CC BY-NC-SA 4.0 by Virtual Assistant, LLC)
- Датасет и веса Наталии («SOVA Dataset (TTS Natasha)» is licensed under CC BY 4.0 by Virtual Assistant, LLC)
Наш SOVA TTS (весь код + модель и датасет Наталии) вы можете свободно использовать для коммерческих задач бесплатно.
Планы
Планы у нас грандиозные, а именно:
- Полноценный нормализатор текста для раскрытия чисел, аббревиатур и сокращений;
- Модуль для решения неоднозначностей в ударениях и словах с буквой «ё»;
- Добавление поддержки ssml;
- Дальнейшие эксперименты с VAE, получение контроля над отдельными словами и фонемами;
- Подготовка эмоционального синтеза, по возможности с контролем уровня эмоции;
- Мультидикторный синтез на одной модели;
- Новые голоса;
- Клонирование голоса;
- Возможный переход на более современные архитектуры типа Flowtron или FastSpeech2;
- Эксперименты с вокодерами: дообучение Waveglow, обучение LPCNet, тестирование MelGAN;
- Оптимизация архитектуры для работы в реальном времени на CPU.
На текущий момент мы продолжаем двигаться в сторону улучшения качества синтеза речи. Если то, что мы делаем, вам интересно – пишите, можем посотрудничать. Как на коммерческих проектах, так и в Open Source.
Все наши наработки доступны тут: наш GitHub
Распознавание речи: SOVA ASR
Синтез речи: SOVA TTS
4 Продвигай соцсети

Сейчас успеха в любой области можно достичь благодаря соцсетям. Поэтому не стоит игнорировать этот инструмент продвижения своего творчества и связи с нужными людьми.
Чтобы сделать свой аккаунт вирусным, придумай какой-нибудь интерактивный формат, за которым будет интересно следить массовой аудитории. Например, озвучивай голоса участников разных шоу на телевизоре с выключенным звуком и публикуй результаты в профиль.
Если это будет забавно, ты обязательно получишь позитивный фидбэк и продвинешься в индустрии.
Ну, и напоследок хочется сказать, что профессия актера озвучки требует немалых усилий и энтузиазма. Как и в любом деле, тут нужно время, чтобы выстрелить и завоевать свое место под солнцем.
Помни, что твой главный инструмент — это голос, поэтому береги его, не срывай и старайся регулярно его прокачивать. Только упорная практика и желание стать профессионалом своего дела помогут тебе добиться успеха.
Озвучка английского текста голосом онлайн
Сервис Google Translator
Озвучка текста онлайн на русском также производится в переводчики от известного поисковика Google. Плюсом у него является то, что вводить можно без ограничений на несколько сот символов и плюс бесплатность. Минус вы не можете скачать озвученный текст. И конечно качество может уступать платным ресурсам.
Для работы с данным переводчиком и озвучивание текста онлайн перейдите на озвучить текст Введите свой текст, а затем нажмите на динамик в нижнем левом углу. Переводчик от Google полезен во многом. Тут можно сделать транскрибацию текста к своему видео, если немного проявить смекалку. Так же можно нажав на микрофон, писать статьи простого диктуя и не нужно печатать. Единственное что потребуется потом, это отредактировать текст.
Сервис Linguatec
Это еще одна онлайн говорилка отличающаяся от своих коллег тем, что имеет ограничения на ввод! Всего 250 символов (за большее придется доплатить).Да и качество среднее. Голос текст онлайн, что бы воспроизвести текст перейдите на сервис. в настройке языка вместо Deutsch выберите Russisch. Выберите женский (Milena) или мужской (Yuri) голос, далее вводите свой текст и нажимаете кнопку Плей.
Сервис Text-to-Speech
Воспроизведение текста голосом онлайн от сервиса Text-to-Speech. В нем рабочий функционал работы повыше. Воспроизвести в нем можно до 1000 символов, качество в не по сравнению с Linguatec тут намного выше. Что бы воспользоваться сервисом просто перейдите СЮДА для приятной работы. На данном сервисе понятно все интуитивно, когда я попал на данный сервис, все было понятно и так. В любом случаи из выпадающего меню выберите русский язык, введите текст а затем нажмите на «Say it»
Сервис IVONA
И последний сервис который обладает на мой взгляд самым качественным движком из выше перечисленных это IVONA. Опять же минус данного сервиса, это, платность. Разработчики изъяли даже возможность онлайн воспроизведение текста голосом пары строк, которое было совсем недавно ИВОНА. Просматривая сервисы для онлайн озвучивания текста на русском я наткнулся на программы, которые нечем не хуже читают текст. Из всех что мне удалось найти, а пока искал и скачивал, что только не подсовывали вместо программ. Вплоть до американского антивируса. Итак… Из всего скаченного, я бы отметил такие продукты как Говорилка и Sacrament Talker.
Какие возможности у онлайн сервисов по озвучиванию текста и зачем они нужны?
Программное обеспечение для озвучки имеют практически одинаковый принцип работы.
Функции сервисов и алгоритм работы:
- Ввод текста или загрузка документа в специальной области.
- После этого запускается установленный Вами движок.
- Далее предлагается выбрать голос.
- Отметьте нужную комфортную скорость чтения
У подобных сервисов есть единственный недостаток – это неправильное произношение, ударение, речевые ошибки. В остальном – они отлично справляются, даже голос уже давно стал максимально похожим на человеческий.
Движки анализа и обработки речи представляют собой специальное программное обеспечение, как драйвера для устройств, подключаемых к компьютеру. Они необходимы для функционирования модуля голоса и запуска читалки, чтобы осуществить преобразование текстовой информации в речь.
Подобное приложение не имеет графического интерфейса взаимодействия и дизайна. Чтобы начать работу с текстом, необходима программа для чтения.
При установке любого сервиса без предварительной загрузки движка информация воспроизводится не будет. Новички зачастую совершают такую ошибку.
Основные стандарты движков:
- SAPI 4 – довольно немолодой, но достаточно надежный стандарт. Качество преобразования и чтения для современного уровня недостаточно хорошее, поэтому на текущий момент практически не используется.
- SAPI 5 – практически самый популярный стандарт, все современные голосовые движки работают под его чутким руководством. Может воспроизводить разные типы голосов и тональности.
- MS Speech Platform – комплекс стандартов и инструментов для функционирования чтения.
Примеры современных движков:
- Тext-to-speech engines (имя — Николай) – это распространенное ПО на русском с мужским голосом, подходит для большого количества сервисов-читалок. Также на сайте есть языковые пакеты для него. Недостаток есть только один – пробный период две недели, поэтому при желании использовать дальше придется оплачивать подписку.
- Acapela (имя – Алена) – это популярный голосовой движок на русском с приятным женским голосом от известной компании. Работает по современному стандарту SAPI-5.
- Катерина 2 – достаточно хорошая реализация речевой функции на русском с приятным женским голосом, который по техническим характеристика сопоставим с TTSE. Постоянно обновляется и происходят доработки голоса. Особенно важным и решающим стало обновление фонетической части и теперь Катя практически не делает ошибок в ударениях.
- RHVoice — современный мультиязычный преобразователь текста в речь с открытым кодом и возможностью самостоятельно настраивать в пользовательском режиме. Используется со всеми операционными системами, действующими на данными момент.
- IVONA Tatyana/Maxim – прогрессивный движок, способный воспроизводить речь как мужским, так и женским голосом. Отличные качество звука, процесс преобразования и отработанная тысячами алгоритмов функция чтения, которая практически никогда не делает речевых и орфографических ошибок. Интонация максимально нероботизирована.
Синтезатор речи (TTS)
Для всех пользователей портала виртуальных офисных инструментов мы ввели бесплатную поддержку современной технологии синтеза речи text-to-speech. Это технология нового поколения, позволяющая генерировать речь напрямую из печатного текста. То есть набранный вами текст может быть произнесен любым выбранным вами голосом, с нужной вам интонацией и скоростью речи.
Каким же способом это происходит и что из себя представляет технология text-to-speech?
Технология text-to-speech сокращенно (TTS) способна формировать любую форму речи (голос или просто речевой сигнал) по простому печатному тексту. Иными словами — это синтез голоса, настолько хорошо генерированный современными программами, что их просто невозможно отличить от настоящего человеческого голоса.
На сегодняшний день text-to-speech является лучшей технологий, способной преобразовывать текст в речь. Причем это могут любые голоса от самых низких мужских до высоких женских и даже роботизированных голосов на нескольких языках.
Основными преимуществами использования этой технологии являются конвертирование и чтение файлов без временных файлов, что способствует экономии места на жестком диске и очень быстрой, почти мгновенной скорости
конвертирования. Кроме того существует возможность поддержки функции МР3 качества и шрифтовых настроек. Очень быстрая скорость работы и удобный пользовательский интерфейс.
Использование технологии синтеза речи
В каждом разделе личного кабинета для управления виртуальной АТС есть кнопка TTS, которая позволяет использовать голосовой движок.
Для того, чтобы сконвертировать текст в речь, нужно зайти в раздел Автоинформатор \ Звуковые файлы и нажать на кнопку «добавить». В появившемся окне нажать кнопку TTS и вставить нужный текст. Затем, указав его идентификатор и описание, нажать кнопку «ОК».
Скачать пример работы функции TTS
Вы можете убедиться в безупречности работы нашего голосового движка для различных услуг виртуальной АТС. Для этого скачайте примеры сгенерированных файлов по ссылкам ниже. Первый пример — это голосовое меню с поддержкой Text to Speech, русский мужской и женский голос.
| Скачать голосовое приветствие мужской голос |
| Скачать голосовое приветствие женский голос |
Второй пример — автоматически сгенерированное сообщение уведомления о текущем балансе для телефонного автоинформатора с поддержкой Text to Speech, русский мужской и женский голос.
| Скачать автоинформатор мужской голос |
| Скачать автоинформатор женский голос |
Поддержка программного интерфейса API Text to Speech
Специальная веб-служба виртуальной АТС поддерживает открытый программный интерфейс API для интеграции голосового движка в приложения телефонии. Самым наглядным примером использования связки телефон и синтез речи — это услуга автоинформатор. Автоинформатор позволяет генерировать текстовые сообщения по маске и POST-запросам, конвертировать их в голос и в автоматическом режиме передавать по телефонным линиям. Ниже представлена ссылка на подробное описание услуги и программного интерфейса TTS.
Гео персонажи
Альбедо
Кой Дао (Khoi Dao)

Вьетнамский «голосовой» актер, который родился в 1999 году. У него довольно большой список озвучивания, но при этом Кой остается весьма скромным человеком с мягким и тонким, истинно азиатским юмором. Он обожает своих кошек! И это отчетливо видно в его Инстаграме.
Нин Гуан
Эрин Эберс (Erin Ebers)

Эрин не любит распространяться о своей личной жизни, однако не скрывает увлечения анимэ и любви к своей работе. Она счастлива в браке, любит котиков и занимается боевыми искусствами. А еще она очень красивая женщина, подарившая свой уникальный голос владычице Нефритового дворца в Геншин Импакт.
Ноэлль
Лаура Фэй Смит (Laura Faye Smith)

Лаура правда похожа на Ноэлль, своего персонажа. Добрая, отзывчивая, она обожает путешествия и сказочные анимэ истории. И все это отражается на ее страничке в инстаграм. Лаура живет насыщенной и интересной жизнью, охотно делясь ею со своими подписчиками.
Чжун Ли
Кит Силверштейн (Keith Silverstein)

Кит – действительно дед, и очень заботливый. Он родился в далеком 1970 году в Нью-Джерси. У него огромная фильмография, есть страничка в Википедии, он постоянно занимается общественной деятельностью и не устает от любимой работы. А еще у него две дочери и маленькая очаровательная внучка, которой Кит в последнее время посвящает весь свой досуг.
Место № 10. Oddcast.com – позволит прочитать текст голосом онлайн на любом языке
Англоязычный сервис oddcast.com может похвастаться имеющимися в его функционале тремя русскими голосами (Dmitri, Milena, Olga), а также приятной визуальной составляющей. При этом воспроизводимые сервисом голоса звучат довольно роботизированно, ударения в словах часто ставятся невпопад. Количество бесплатно воспроизводимых предложений ограничено парой сотен символов (за большее придётся доплачивать).
Чтобы озвучить необходимый текст, нужно проделать следующие действия:
- Запустите oddcast.com, в опции «Language» выберите «Russian».
- В опции «Voice» выберите один из представленных голосов.
- В окне «Enter text» введите ваш текст.
- Затем нажмите на кнопку «Say It» для прочтения слов голосом.
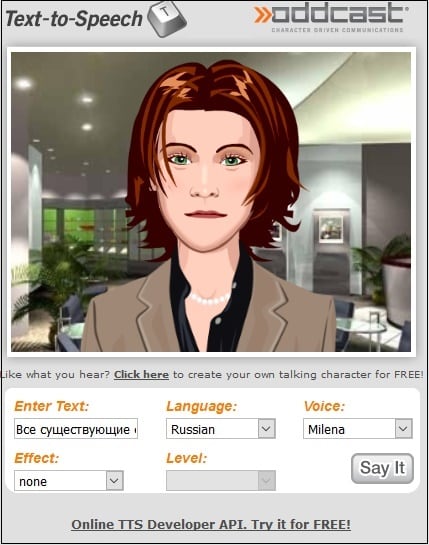 Визуально приятный oddcast.com
Визуально приятный oddcast.com
Как озвучить текст документа в Ворде — функция «Прочитать вслух»
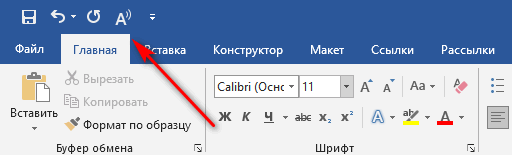
Сначала мы разберемся, как использовать в Ворд чтение вслух в версии программы Microsoft Word 2019. Этой функцией в редакторе можно управлять из окна документа или с помощью «горячих» клавиш.
Выполните следующие действия:
- В окне открытого документа Word откройте вкладку «Рецензирование».
- В группе «Речь» находится кнопка «Прочесть вслух».

- Нажмите на кнопку «Прочесть вслух» для запуска процесса чтения вслух текста документа Word.
- После этого робот голосом диктора начинает читать текст.
- В правом верхнем углу, под лентой меню откроется небольшая панель управления с настройками чтения. С помощью кнопок можно отключить или поставить на паузу речь диктора, перейти назад или вперед по тексту документа, настроить скорость чтения, выбрать голосовой движок.
- Нажмите на кнопку «Настройки», чтобы отрегулировать скорость чтения или выбрать подходящий голос. В программе доступны два голоса:
- Женский — Microsoft Irina («Ирина»).
- Мужской — Microsoft Pavel («Павел»).
По умолчанию робот прочтет весь текст документа, находящийся после курсора мыши. Чтобы прочитать только кусок текста, выделите нужный фрагмент документа.
Если вам неудобно для запуска процесса чтения все время открывать вкладку «Рецензирование», вы можете закрепить кнопку «Прочесть вслух» на панели быстрого доступа.
Пройдите шаги:
- Откройте «Параметры».
- В окне «Параметры Word» войдите во вкладку «Панель быстрого доступа».
- В поле «Выбрать команды из:» укажите «Все команды».
- В левой области найдите и выделите инструмент «Прочесть вслух».
- Нажмите на кнопку «Добавить».
- После того, как эта команда появилась в правой колонке, нажмите на кнопку «ОК».

На панели быстрого доступа появится значок, с помощью которого можно запускать функцию «Прочесть вслух».
Как сжать документ Word — 13 способов
3 Найди агента
Если ты понимаешь, что в одиночку тебе не справиться, советуем найти грамотного агента, который будет представлять твои интересы и связывать с нужными проектами.
Такой человек будет своевременно сообщать тебе о кастингах, продвигать в индустрии, общаться с аудиторией, оговаривать финансовые вопросы с заказчиками и, конечно же, получать от этих денег какой-то процент.
Тем не менее плюс агента заключается в том, что он будет находить возможности, о которых ты даже не подозревал. Таким образом, у многих актеров есть свои агенты, которые берут всю волокиту на себя.
Чтобы законнектиться с таким человеком, необходимо отправить ему свое резюме и портфолио, чтобы он четко понимал, насколько перспективным и взаимовыгодным будет ваше сотрудничество.
Популярные голосовые движки
Звучание голоса в синтезаторе речи зависит от того, какой в нем используется движок. Например, в русских версиях Windows установлен “электронный диктор” Microsoft Irina. Если в синтезаторе речи нет другого движка, то по умолчанию будет говорить именно она. При этом выбор голосов на самом деле очень богатый. Среди популярных русских движков можно выделить:
- Alyona от Acapela Group
- Татьяна и Максим от Ivona
- Ольга и Дмитрий от Loquendo
- Милена, Катерина и Юрий от Nuance
- Николай от Speech Cube Elan
Движки отличаются тембром голоса, эмоциональной окраской, количеством встроенных словарей, которые определяют правильность речи. Например, Николай читает текст практически без эмоций, поэтому с ним сложно воспринимать художественные тексты, а Ольга и Дмитрий от Loquendo, наоборот, используют разные стили речи. Все перечисленные движки работают по стандарту SAPI 5, который применяется на Windows, начиная с версии XP.

Большинство движков представлены в двух вариантах — мужской и женский голос. Детских голосов мало. Даже на сайте Acapela Group, одного из лидеров индустрии, меньше 10 языков, для которых доступны голоса детей.
Как сказано выше, голосовые движки облегчают процесс изучения иностранных языков. Например, Lernout&Hauspie предлагает для этого бесплатные голоса с американским и британским акцентами английского,а также голландским, испанским, итальянским и другим произношением. Большое количество движков разработала компания Cepstral. У них также есть бесплатная версия электронного диктора, однако при ее использовании постоянно появляется окно с предложением перейти на платный тариф.
Несмотря на то, что голосовые движки становятся всё более технологичными, добиться 100% совпадения с живой человеческой речью не удалось пока никому. Вам достаточно услышать несколько предложений, чтобы понять, что говорит робот. При изучении иностранных слов не стоит полагаться только на произношение программ — они нередко ошибаются. Но если ваша задача — простое озвучивание информации на русском, то можно использовать любой движок, в базе которого есть этот язык.
Чтобы добавить голосовой движок в Windows, достаточно его скачать и установить как обычную программу. После этого он появится в списке доступных. Но для использования голосов необходима сторонняя программа или веб-сервис, так как сами движки не имеют графического интерфейса.
Приложения для чтения книг голосом
Чтобы выбрать лучшую программу для озвучивания текста, нужно перебрать разные варианты читалок. Каждая из этих программ получила свою аудиторию – кому-то нравится оформление, а другим универсальность и малое потребление ресурсов ПК. Прежде чем скачивать и ставить приложение на свой компьютер рекомендуют предварительно просмотреть подробную информацию по наиболее популярным.
Acapela
Речевой синтезатор, который может воспроизводить голосом текст из файлов разного формата. Пакет насчитывает больше 30 языков, среди которых присутствует и русский. Программу Acapela можно купить у разработчика – ее распространяют только на коммерческой основе. Для озвучивания книги на русском языке, пользователь может выбрать один из 2 предустановленных вариантов – устаревший мужской голос «Николай» и обновленный женский «Алена». Программу выпускают под управлением таких систем:
- Windows;
- Mac;
- Linux;
- Android;
- iOS.
Такое широкое распространение позволяет использовать Acapela любому пользователю. Сама программа не занимает много места на устройстве и устанавливается очень быстро. Для предварительной оценки, пользователи могут включить онлайн-версию приложения. Но, количество текста ограничено 300 знаками, поэтому включить книгу не получится, только краткий отрывок для проверки качества озвучки.
Ivona Reader
Программа для озвучивания текстов под управлением Windows, с реалистичным звучанием. Основной голос, который можно поставить на это приложение – «Татьяна». Может зачитывать текстовые файлы в любом формате, в том числе интернет страницы и RSS ленты. Разработчики также включили возможность преобразования текста в аудио-файл MP3 формата, поэтому книгу можно записать и сбросить на смартфон.
ICE Book Reader Professional
Программа, которая знакома пользователям компьютеров Windows уже давно. Она поддерживает большую часть текстовых форматов и проста в управлении. Для использования функции чтения и преобразования текста в аудиозапись, обязательно установить какой-либо голосовой движок. ICE Book Reader – относят к категории приложений с лицензией Freeware – ее можно получить бесплатно и пользоваться всеми функциями.
ToM Reader
https://youtube.com/watch?v=DUXBPLwXT2Q
Эта программа для компьютеров под управлением операционных систем Windows – аналог ICE Book Reader. Работает сходным образом – открывает книги в разных текстовых форматах и может озвучивать только после установки одного из голосовых движков. Для улучшения качеств воспроизведения есть возможность добавлять словари, по которым ориентируется синтезатор.
Программы, которые способны озвучивать текст голосом, становятся распространенней – при активном ритме жизни, не у каждого человека найдется время на чтение обычного буквенного формата. Но, в таких ситуациях можно не только скачивать заготовленные аудиокниги – установив читающую программу и голосовой движок, такой файл можно подготовить самостоятельно или озвучить интересующую информацию в потоковом режиме. Современное ПО синтеза речи, по звучанию приближено к реальному голосу.
Озвучка текста естественным голосом с помощью нейронной технологии WaveNet
Компания Гугл продолжает разработки технологии «текст в речь» (Text-to-Speech), активно реализуя наработки в приложениях «Google Assistant» и «Maps». Ныне результаты доступны в облачной платформе от Гугл («Google Cloud Platform»). Основой новацией стала модель WaweNet от Гугл, позволяющая поддерживать 32 опции голоса на 12 языках, настройку тона голоса, его громкости и другие возможности.
| Параметры | WaveNet |
| Доступ в режиме офлайн | Нет |
| Настройка тона голоса | Есть |
| Качество звучания | На 20% лучше, чем у аналогов |
| Поддержка русского языка | Нет |
Данная модель разрабатывается командой Гугл под названием DeepMind, анонсировавшей выход WaveNet ещё в 2020 году. Вместо использования фрагментов речи и соединения их в слова (что звучит довольно роботизировано), WaveNet формирует индивидуальные голосовые волны, тем самым создавая естественную голосовую речь. В процессе разработки Гугл улучшил возможности WaveNet, сделав её намного быстрее, а воспроизводимый ею голос – качественнее. В проводящихся тестах слушатели отметили улучшение звучания на 20% по сравнению с альтернативными голосами конкурирующих проектов.
WaveNet показывает улучшенные результаты по сравнению с конкурентами
Как воспользоваться услугой:
- Демонстрационный режим новой технологии доступен на cloud.google.com.
- Перейдите по данной ссылке, промотайте её чуть вниз до слов «Convert your text to speech right now», и нажмите на кнопку «SPEAK IT».
К сожалению, русский язык на данный момент не поддерживается (находится в разработке). Впрочем, даже английского произношения достаточно, чтобы оценить высокий уровень проговаривания текста голосом от Гугл.

Нажмите на «SPEAK IT» для демонстрации работы технологии «WaveNet»
6 Запишись на курсы актерского мастерства
Несмотря на то, что актеру озвучки не нужно появляться в кадре, большим плюсом для него будет владение самыми настоящими навыками игры на сцене. Поверь, это в разы облегчает работу над материалом.
С одной стороны, работа актера озвучки даже может быть сложнее классической работы актера, потому что единственным инструментом, которым орудует аудиал — это его голос. С помощью него необходимо передать весь спектр эмоций, а также подстроиться под выражение лица, жестикуляцию и движения персонажа в кадре.
Таким образом, все надо сделать с помощью голоса, а это далеко не самая простая задача.
BookSeer
Bookseer
Бесплатная каталог-читалка электронных книг, у которой имеются различные нужные функции.
Имеется распределитель документных источников с информацией о значимых документах, которые здесь возможно просмотреть; база данных совокупного использования (Web адреса , почта, коллекции, записи).
В данном приложении регистрироваться не нужно.
Персональные опции программы:
- Создание архива данных в едином документе (*.bon) и простейшая эксплуатация этого архива;
- По ссылкам, прописанным в архиве данных, запускается любая программа;
- Интегрированными инструментами возможно прочитать любой текстовый документ (TXT, RTF, HTML, DOC и т.п.) с автодекодированием DOS->WIN, KOI->WIN;
- Чтение и открытие документы возможно сразу из хранилищ (Zip, Rar, Ha), которые приложение распознаёт без внешних распаковщиков;
- По ссылкам, записанным в базе, приложение выполняет массовые действия напрямую с документами на диске: переименование, дублирование, перенесение, исключение;
- Возможность отдельного использования базы — как структурированный склад текстов, без ссылки на документы, пользуясь полями базы и изменять им название по желанию;
- Неограниченное количество баз данных — для разных целей, со персональными наладками.
ПЛЮСЫ:
- имеется распределитель документных источников
- неограниченное количество баз данных
- Работа с архивами ZIP
МИНУСЫ:
нет выравнивания текста
На сайт
Краткий Обзор Решений
Данная статья не ставит своей целью глубокий технический обзор всех доступных решений. Мы хотим просто обрисовать некий ландшафт из доступных вариантов с минимальной степенью готовности. Понятно, что мы не рассматриваем многочисленные тулкиты, а смотрим в первую очередь какие есть более-менее готовые решения с ненулевой библиотекой голосов и подобием поддержки / комьюнити:
Конкатенативные модели (появившиеся до DL бума). Из того, что хоть как-то поддерживается и живо и можно запустить «as-is» без археологических раскопок, я нашел только rhvoice (я глубоко не копал, но есть целые форумы, посвященные использованию голосов из Windows, но вряд ли это можно назвать поддерживаемым решением). На момент, когда я пользовался проектом ради интереса, он по сути был заброшен, но потом у него появился новый «хозяин». К плюсам такого рода решений можно отнести их скорость и нетребовательность к ресурсам (исключая ресурсы, чтобы заставить это работать). Очевидный и основной минус — звучит как говорилка. Менее очевидный минус — довольно тяжело оценить стоимость обладания. Качество звучания: 3+ по пятибалльной шкале;
DL-based модели в основном разделяют end-to-end TTS задачу на подзадачи: текст -> фичи и фичи -> речь (вокодинг). Практически повсеместно для первой подзадачи используется Tacotron2. Выделим следующие сочетания моделей в соответствии с их эффективностью и простотой использования:
Tacotron2 + WaveNet (оригинальный WaveNet принимал на вход лингвофичи, но для такотрона поменяли на более удобные мелспектрограммы). Основная проблема — очень медленный инференс ввиду авторегрессионности модели и необходимость запретительно большого количества ресурсов и времени. Качество звучания: 4+;
Tacotron2 + WaveRNN (тоже с переходом от лингвофичей к спектрограммам). Вокодер заметно быстрее предыдущего: при использовании всех хаков можно получить даже риалтайм синтез без GPU, правда естественность звука несколько просядет. Качество звучания: 3.5-4;
Tacotron2 + Parallel WaveNet. Упомянутый выше медленный вокодер был использован в качестве учителя для получения новой довольно быстрой параллельной модели вокодера: с ней стал возможен синтез быстрее риалтайма, но все еще на мощных GPU. Из недостатков — дистилляция требует качественную учительскую модель и соответствующую схему обучения. Качество звучания: 4+;
Tacotron2 + multi-band WaveRNN. Тоже развитие предыдущих идей, тоже распараллеливание в некотором смысле — здесь доступен синтез быстрее риалтайма уже на CPU. Однако, не слишком популярная работа, меньше имплементаций и поддержки, хотя некоторые подходы хороши и были успешно использованы в более поздних моделях; Качество звучания: 3.5-4+;
Tacotron2 + LPCNet. Интересная идея про сочетание DL и классических алгоритмов, что может дать буст по скорости до подходящего для продакшена уровня и на CPU, но требует вдумчивого допиливания для качественных результатов. Качество звучания: 3.5-4+;
Многочисленные решения на базе Tacotron2 + Waveglow от Nvidia как нынешний стандарт для задачи синтеза речи. Никто не пишет про свой «секретный соус» (например как 15.ai делает голос по 15 минутам и сколько там моделей в цепочке). Есть много имплементаций и репозиториев, которые «копируют» чужой код. Может звучать на cherry-picked примерах неотличимо от живых людей, но когда смотришь реальные модели от комьюнити, качество заметно варьируется, а детали улучшенных решений не раскрываются. Архитектурно к такотрону и его аналогам по скорости и цене обладания претензий нет, но Waveglow очень прожорлив к ресурсам как на тренировке, так и в продакшене, что делает его использование по сути нецелесообразным. Качество звучания: 3.5-4+;
Замена Tacotron2 => FastSpeech / FastSpeech 2 / FastPitch, то есть уход к более простой сетке (на базе forced-align от такотрона и миллион более хитрых и сложных вариантов). Из полезного дает контроль темпа речи и высоты голоса, что неплохо, вообще упрощает и делает более модульной конечную архитектуру
Немаловажно, что сетка перестает быть рекуррентной, что открывает просторы для оптимизаций по скорости. Качество звучания: 3.5-4+;